





削減後の株式の上昇:市場概要")

ウェブサイトの情報を自動的に取得するウェブスクレイピング情報収集プログラムに任せて時間を節約することができるだけでなく、毎回同じ作業を正確に行うことができ、ヒューマンエラーの防止にも役立ちます。そのようなウェブスクレイピングをJavaScriptアロハ方法エンジニアパベルプロクディン氏が、サンプルコードを使用して説明しています。
JSでウェブスクレイピング| アナログ森
https://qoob.cc/web-scraping/
ウェブスクレイピングツールは、プログラミング言語にPython 3、HTMLの取得にリクエストライブラリのHTML解析美しいスープが頻繁に使用されます。 しかし、このツールによるれる技術は、数年前から変化がないうえ、JavaScriptエンジニアに利用コストが高いとProkudinは指摘した。 今JavaScriptで、Webスクレイピングをしたい人のための文書を整備したいとProkudin氏は述べています。
◆データを事前確認
まず、Webスクレイピングする前に、「Webスクレピンガ必要かどうか」を確認しなければならないProkudinさんはアドバイスしています。最近のWebアプリケーションは、HTMLにデータを直接作成するのではなく、構造化されたデータを動的に生成する場合が多いので、元のウェブスクレイピングをしなくてもデータを取得する場合が多いとのこと。
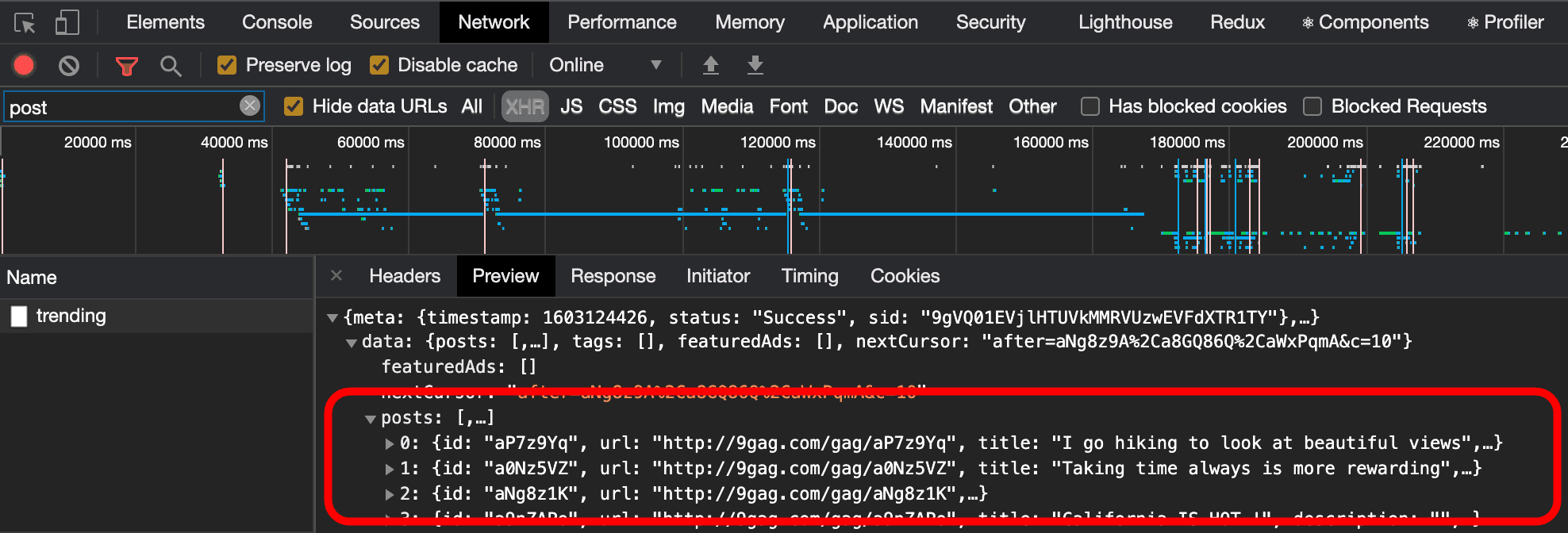
◆データを取得する
ウェブスクレピンガ必要に応じて、まず、WebサイトのHTMLデータ自体を取得します。Node.jsのHTTPS標準モジュールをそのまま利用することも可能だが、Prokudin氏は、非同期処理に対応しているノードをインポート推奨次のコードでは、サッカーの試合結果などの情報を提供するウェブサイト「
Transfermarkt“でリオネル・メッシ選手のページのHTMLを取得することができます。
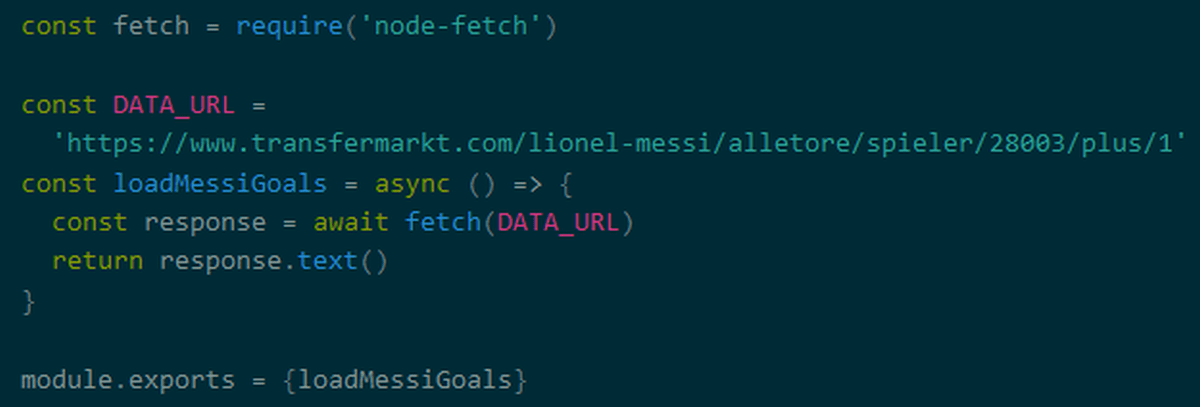
◆データを分析する
取得したHTMLを解釈するためのツールは、こんにちはやjsdomなどがあり、Prokudin氏は、サンプルコードでjsdomを使用しています。 まず取得したHTMLをプログラムが動作するようにするためには、ドキュメントオブジェクトモデル(DOM)を作りました。

作成されたDOMでたい情報が存在する部分のCSSセレクタを指定してNodeListオブジェクトを生成します。そのArray.from()メソッドを使用してNodeListオブジェクトをArrayオブジェクトに変換します。 これで、目的の情報を扱いやすい配列の形で得ることができました。

◆データを処理する
取得した配列に不要な情報が含まれているため、必要な情報だけを残すように処理をすること。 Prokudinさんのサンプルコードでは、配列の行の長さを取得して、データの形状を調査しています。 今回のサンプルコードでは、取得した配列は、長さが1,5,14,15の4つの長さのラインを持っています。

行の長さに応じ処理を追加します。 長さが15行は、最初から5番目までの値と6回目以降の値に分離する。

そのほかにもProkudinさんのコードは、長さが1行は除外する処理が行われています。
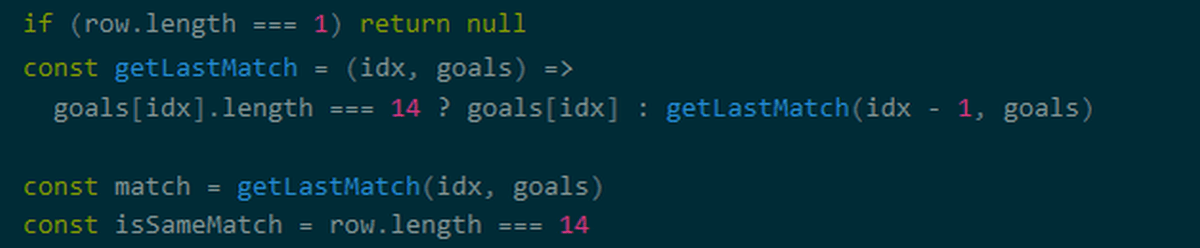
最後に、配列の値をマッピングすると、データの処理は完了します。
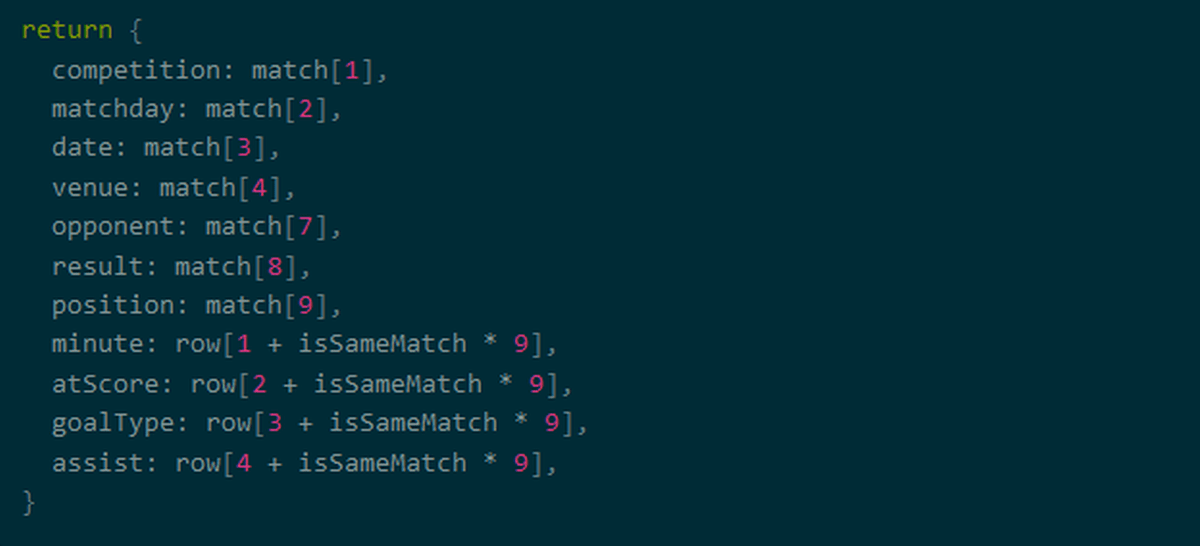
◆データの保存
残りは処理されたデータを保存すればOK。 今Pythonを使用せずにWeb廃棄することができます。

Prokudin氏のチュートリアルで使用されたすべてのサンプルコードは、CodeSandbox公開されています。
この記事のタイトルとURLをコピー





+ There are no comments
Add yours