





削減後の株式の上昇:市場概要")

AMDのCPU「Ryzen 5000」シリーズはTSMCの7nm工程を採用したZen 3アーキテクチャのデスクトップCPUで2020年11月5日に登場します。 このZen 3アーキテクチャは、技術ベースのメディアAnandTechが、AMDの最高技術責任者(CTO)であるマーク・ペーパーマスター氏にインタビューを実施しています。
AMD Zen 3:CTO Mark PapermasterとAnandTechのインタビュー
https://www.anandtech.com/show/16176/amd-zen-3-an-anandtech-interview-with-cto-mark-papermaster
キュー:
Ryzenを初めて発表したとき、社長兼CEOであるリサス氏にインタビューしたとき、彼女は、AMDのポジショニングが新しい高性能x86アーキテクチャを開発するためにAMDがどのように固定観念にとらわれない思考をするのに役立ったかについて教えてくださいました。
Ryzenで復活の狼煙を上げたAMDのリサズCEOインタビュー – GIGAZINE

AMDが市場の性能のリーダーシップを主張している今、AMDのエンジニアリングチームは、どのようにして現象に起因独創的な考えを続けて推進しているのでしょうか?
紙マスターCTO:
私たちのチームは、業界で最も革新的なエンジニアリングチームのいずれかであることを非常に誇りに思っています。 Zen 3 CPUの発表は、CPUの市場でのリーダーシップという地位を獲得するための熾烈な戦いであり、その後も非常に強力なロードマップがあります。 Zen 3で採用した方式は、パフォーマンスを向上させる特効薬ではないことは、見れば理解いただけると思います。 CPU全体のほぼすべてのデバイスに触れることができ、チームは、パフォーマンスの向上、効率の向上、メモリ遅延を減らしてパフォーマンスの大幅な向上を実現する優れた仕事を行いました。

2019年半ばに発売されたばかりZen 2つのCPUと比較してZen 3 CPUは、クロックあたりの命令実行数(IPC)が19%向上しました。 これは驚くべき成果であり、私は「ハードコアエンジニアリング」と呼ばれる焦点を当てたもので、チームは今後も継続することです。
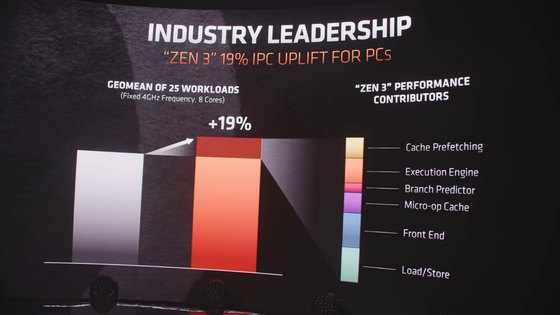
キュー:
この「19%の価値」を強調するためにZen 2に比べてクロックあたりの性能が19%向上しただけでなく、「8コア」と「32MBのL3キャッシュ」を含む新しいコアコンプレックス(CCX)が、AMDの発表で強調された。CCXはZenマイクロアーキテクチャで、「4コア8スレッド+ 8MB L3キャッシュ」を一つのCPUモジュールで構成するAMD独自の単位です。2020年4月に発表された “Ryzen 3 3300X“はCCXが「4コア8スレッド+ 16MB L3キャッシュ」でZen 3アーキテクチャは、「8コア16スレッド+ 32MB L3キャッシュ」に変更されています。

この新しいCCXデザインは本来の性能向上にどのように役立つのだろうか? また、新たに統合されたCCXに切り替えて、CPU設計に一つの大きな利点がありますか?
紙マスターCTO:
CCXの基本構成の変更は、ゲームの膨大なメモリに遅延の低減を実現するために非常に重要でした。 ゲームの目的は、高性能デスクトップPC市場で非常に重要です。 そして、その性能は、使用可能なL3キャッシュに非常に依存しています。 これは、ローカルL3キャッシュヒットしたとしても、明らかにメインメモリ参照をたどっていないからです。
したがってCCXを再構成して、16MBのL3キャッシュに直接アクセスすることができるコアを4倍にすることで、32MBのL3キャッシュに直接アクセスすることができるコアを8個に増やすことができました。 これは待機時間を減らし、最大の手段です。 明らかにキャッシュヒットすると、効果的な遅延を得ることができます。 これは、パフォーマンスを直接向上します。
キュー:
各コアのL3キャッシュへのアクセスを16MBから32MBに倍増することは大きな飛躍です。 全体の遅延が最大32MBまで改善されることで、メインメモリにアクセスする必要がありません。 しかし、サイズを2倍にすることはできL3の遅延範囲に影響を与えていますか? L3キャッシュを2倍にするとそれにアクセスするコアの数が増加した場合でも、明らかに欠点が生じます。
紙マスターCTO:
開発チームは、論理的にも肉体的にも技術面で素晴らしい仕事をしました。 核心は「再構成をどのように設計するか “、そして”新しい構造をサポートするロジックを変更して、実際の実装にも同様に焦点を当てる?」ということです。Zen 3コアの再構成は、遅延の減少という利点を本当に持っている良いエンジニアリングがいました。
一般的に、コア数を増やすと消費電力が増加します。 また、技術ノード変更せずに7nm工程ままでした。 開発チームは、単に新しいCCXを管理するだけでなく、実装のすべての側面を管理する巨大な仕事をしてZen 3 Zen 2と同じパワーエンベロープを維持しました。 したがって、同じAM4ソケットのようなパワーエンベロープを維持しながら、非常に大きな性能向上を実現しています。
キュー:
プロセス・ノードといえば、Zen 3アーキテクチャで採用されているのは、TSMCの7nmということでした。例えば、Ryzen 3000XTは、製造工程のマイナーアップデートが採用されたことが知られています。 Ryzen 5000製造工程を経て得られた付加的な利点がありますか?
紙マスターCTO:
実際には、コアは、同じ7nmノードにあり、プロセス・デザイン・キット(PDK)が同じであることを意味します。 トランジスタを見ると、製造工場での設計指針が同じになります。 もちろん、いくつかの半導体製造のノードで歩留まり向上などのために製造工程を調整することができます。 四半期ごとのプロセスの違いは、時間の経過に応じて減少しています。 7nmの「些細な偏差」と言うのは、そのようなものです。

キュー:
Zen 2でZen 3に移行すると、1ワットあたりのパフォーマンスが24%向上しています。 これは明らかに、電力供給レベルでさらなる改善が行われたことを意味します。
紙マスターCTO:
私たちは、電源管理なんと力を入れました。 私たちは、全体的なCPUのマイクロコントローラと電源管理制度があります。 したがってZen 3開発チームが24%の電力の向上を達成したことを非常に誇りに思っています。 これは、チップの多数のセンサーに常に耳を傾けながら、周波数と電圧の両方をより効果的に管理できるようにするためには、精密ブースト全体をさらに発展させたものです。 これは、マイクロプロセッサ上で実行されるワークロードに合わせて電力管理が可能です。 つまり、応答性が高く、しかも効率も高いということです。
キュー:
Zen 2で指摘された点の一つは、I / Oダイ待機消費電力が13ワットで20ワットの比較的高いものでした。 Zen 3のアーキテクチャは、Zen 2のようなI / Oダイを使用することが知られています。 I / Oと消費電力のAMDの目標についてですが、AMDは7nmでPCI Express 4.0に対応していますが、I / OダイGlobalFoundries12 / 14nmプロセスをベースにしています。 I / OはRyzenに今後の改善の鍵になると思いますか?

紙マスターCTO:
これは世代のものであり、将来を見据えた場合、我々はすべての世代で改善を推進しています。そのため、AMDはPCI Express 5.0とエコシステム全体に移行することになるでしょう。設計されている次世代のコアだけでなく、次世代のI / Oとメモリコントローラすべての改善については、次のステップでは、我々の報告があると予想されます。
キュー:
クライアントと企業の両方のx86アーキテクチャCPU市場は非常に競争が激しくなっているが、両方の市場で腕エコシステムでの圧力が高まっていることは否定できません。現在のArm自体Neoverse V1デザインは、x86に近いレベルのIPCと前年比30%の性能向上をx86を実行する電力の一部に実現するために努力しています。 これまでAMDの目的は、Zen 3のように、ピーク性能を達成することがあったが、特にロードマップで、より高いパフォーマンスを約束しているAMDはどのようにしてArmとの競争に対抗しようと、同じでしょうか?

紙マスターCTO:
私たちは、性能面では、アクセルを踏まないようにしています。命令セットアーキテクチャ(ISA)の問題がありません。 いくつかのISAにも一度、高性能を目指すなら、その性能を達成するためにトランジスタを追加することができます。 ISAと他のISAの間に若干の違いがありますが、それの基本的なことは、ありません。 私たちは、設計上のx86を選んだのは、膨大なソフトウェアのインストールベースとそこにある膨大なツールチェーンがあったからです。 これは、業界で最初に採用される道ができました。 私たちは、歴史的に競争環境の中で生きてきたが、今後もそれが変わるとは思わない。 私たちの見解は、「最大の防御は攻撃」ということです。
キュー:
Zen 3小パフォーマンスが大幅に改善されたことで、AMDがCPUベースのAI加速どのようにアクセスしているかについては、あまり話題にされていません。 単純にコアを持っており、浮動小数点演算性能が強いのか、それとも加速と最適化されたコマンドの範囲があるでしょう。
紙マスターCTO:
Zen 3で重視したのは、牛の性能です。 Zen 2は、多くの分野でリーダーシップを発揮する性能がありましたが、Zen 3への移行では、パフォーマンスに絶対的なリーダーシップを実現することを目的としていました。

だから浮動小数点演算と積和演算改善してベクトル処理と推論などのAIワークロードをサポートすることができます。 これにより、さまざまなワークロードに対応できるようになります。 また、最大ブースト周波数は “潮はすべての船を上げる」のような周波数を増加しました。しかし、新しい数学の形式は、現在発表していません。
キュー:
は、AMDはAIワークロードに対してZen 3の加速ライブラリを既に準備しているのでしょうか?
紙マスターCTO:
はい、そうです。 私たちは、Zen 3を中心に最適化するマス・カーネル・ライブラリーを提供しています。 これは毎年拡張されていく予定です。
キュー:
AMDはChromebookやAMDの招待Zenアーキテクチャの基本的な技術など、これまであまり高い市場シェアを誇るていない他の市場にも進出しています。 AMDは今後もこの市場に特化していくのでしょうか。 それともIoTや自動車など、AMDが特に努力なかった市場に隠れ可能性があるでしょう。
紙マスターCTO:
私たちは、現在の市場に比べて密接市場に注目しています。 私たちは、これまで組み込み機器市場に進出してシェアを伸ばしており、AMDはこれに重点を置いています。 私たちが何をしないのは、メディアの注目度は高いかもしれないが、AMDが持っているように高い性能と驚くほど一致していない市場を追求することです。 私たちは、業界の貴重な高性能を提供したいと考えて、私たちが提供することができることを本当に価値があると評価してくれるの市場シェア獲得に注力しています。
この記事のタイトルとURLをコピー


")
![元F1チャンピオンニコ・ロズベルグ、自分のエクストリームEチームを設立[F1-Gate.com]](https://f1-gate.com/media/img2020/20201022-f1-nico-rosberg-extremee.jpg "元F1チャンピオンニコ・ロズベルグ、自分のエクストリームEチームを設立[F1-Gate.com]")

+ There are no comments
Add yours